Heute geht es weiter mit Fallbeispielen dafür, wie man den Schwung von Big Data mitnimmt, um Unternehmen datengetriebener zu machen. Wir wissen schon: Die Betriebswirte sollen die Informatik führen, wenn es um Big Data geht. Oder wie Trekkies sagen würden: Es braucht nicht nur Spock, sondern auch besonders viel Kirk, damit aus Big Data kein Flop wird.
Mein Sohn (17) bestand den Raumschiff-Enterprise-Test gerade so. Er hatte von Kirk und Spock gehört, würde Spock wohl wiedererkennen – das war’s. Bei Nerds älteren Semesters scheint das anders zu sein. Jedenfalls kam die Enterprise auf einer Podiumsdiskussion über Big Data zu einiger Ehre. Mehrfach stand der Vulkanier Spock Pate für den kühlen, logischen Verstand automatisierter, maschineller Analysen. Sehr gut!

Die WAMS findet: „Auch wenn Big Data zu nichts führt, kann es gut aussehen.“ Hilft oder schadet am Ende solch ein Frohsinn? Wir wissen es (noch) nicht. Quelle: WAMS vom 03.03.2013, S. 52.
Captain Kirk wiederum stand für die menschliche Erfahrung, mit der erst Analysen zu Entscheidungen werden. Großartig! Wenn das keine Metapher für die grundsolide Ansicht ist, dass es Aufgabe des Controllings ist, die Daten zu bändigen, in Form zu gießen und das, was die Daten hergeben, prägnant zu visualisieren. Der Manager bringt dann assoziativ Erfahrungswissen ein und den Willen, Zukunft nicht zu prognostizieren, sondern zu gestalten, und entscheidet. Immerhin der Technikchef von Amazon sah das in der Podiumsdiskussion anders, nahm den Phaser und erschoss kurzerhand Captain Kirk. Jeff Bezos sei Spock, Kirk brauche man nicht, sagte er. Oha.
Vielleicht lässt sich der Konflikt lösen, indem wir in der Reihe der Fallbeispiele fortfahren:
Fallbeispiel 3: Wie die Schüchternheit von Datenanalyseexperten und Technikgläubigkeit von Anwendern zu halbgaren Modellen führen können, aus denen dann Investitionsruinen werden
Jetzt menschelt es: An Datenanalyseprojekten sind meist mehrere Abteilungen und externe Experten beteiligt. Irgendjemand ist immer dagegen und sorgt für Sportlichkeit: Der Experte bekommt erst einmal lieblos zusammengestellte Daten und soll beweisen, was er kann. Das tut er und bekommt tatsächlich etwas heraus, aber das Modell ist so schräg wie die Testdaten. Es kommt zur Präsentation: Das Management hat es wie immer eilig. Die IT hält sich ohnehin zurück, soweit es um den Inhalt geht. Die Fachabteilung hat jemanden entsendet, der für das Projekt ist, aber das Budget nicht erweitern kann. Der Experte steckt in der Klemme: Eigentlich braucht er mehr und bessere Daten, das bedeutet aber mehr Aufwand, wie soll er das einfordern? Jetzt muss der Experte entweder selbst Betriebswirt genug sein, um die Geschäftsleitung in ihrer Sprache zu erreichen oder jemanden dabei haben, der das kann. Der wiederum muss das Problem des Experten verstehen, das dieser wahrscheinlich viel zu mathematisch ausdrücken wird. Die Wahrscheinlichkeit ist groß, dass der Experte glaubt, die Modellmängel ließen sich später noch korrigieren und zu allem nickt. Das Rezept dagegen ist einfach: Manager verstehen jedes Data-Mining-Modell, wenn es vernünftig erklärt wird (wir werden das im nächsten Posting anhand des Amazon-Algorithmus belegen). Eine solche Erklärung sollten sie einfordern. In einem eigenen Projekt für einen Anbieter von Netzwerktechnik mussten wir im Auswahlprozess gegen unser eigenes Testmodell argumentieren. Das Modell konnte mit 80 % Genauigkeit für Geschäftskunden vorhersagen, ob der Umsatz mit dem Sortiment im Folgejahr größer oder kleiner als im abgelaufenen Jahr sein würde. Es konnte mangels Daten aber keine Reihung der Kunden ermitteln. Aus unserer Sicht war das aber die Kernfrage, schließlich ging es darum, welche Kunden in der knappen Arbeitszeit am besten anzusprechen wären. Dafür brauchten wir zusätzliche Daten zu den Vertriebsaktivitäten. In unserem Fall bekamen wir sie und das Modell wurde produktiv, selbstverständlich ist das nicht. Als Nachfrager sollten Sie von großer Schüchternheit technisch orientierter Experten ausgehen. Mit Big Data steigt die Anzahl der Beteiligten und mit ihr das Problem dramatisch, weil zur Schüchternheit noch Politik anderer Beteiligter hinzukommt.
Fallbeispiel 4: Wenn man an das „Ende der Theorien“ glaubt, steht man in der Praxis am Anfang vom Ende
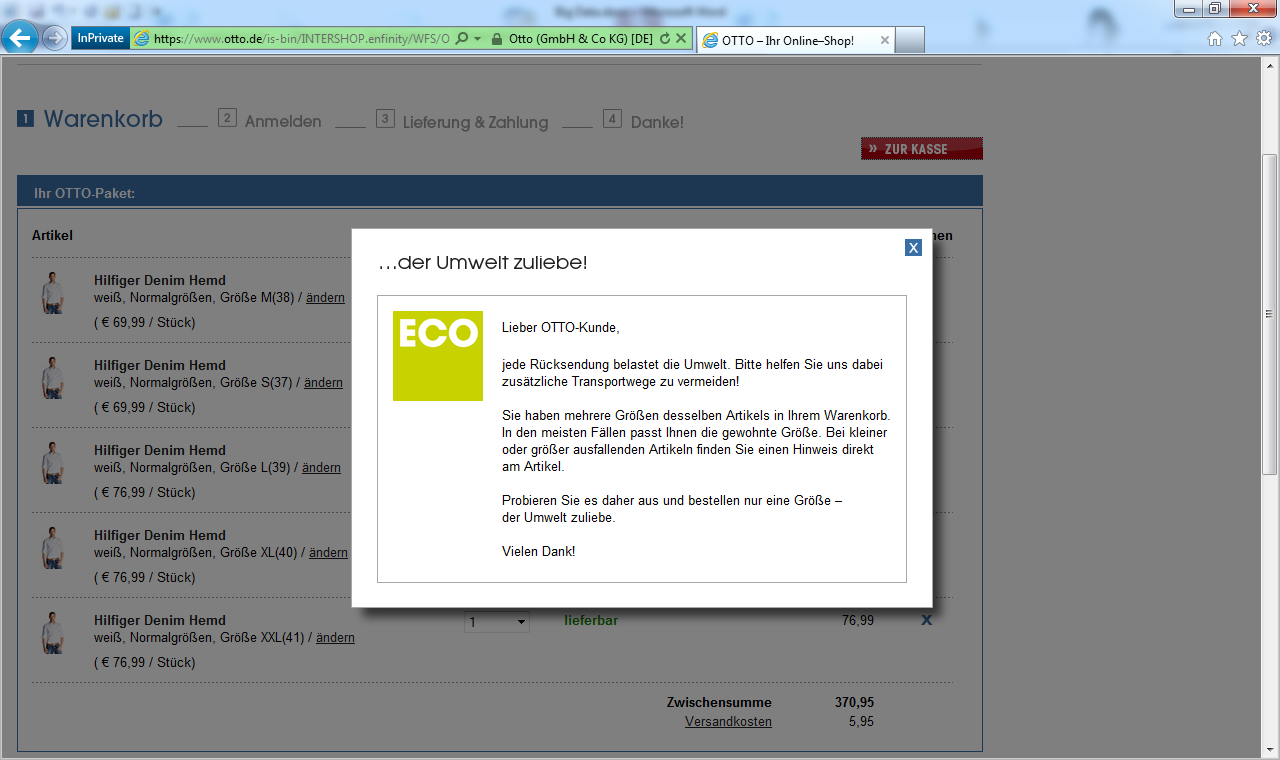
Chris Anderson, ehemals Chefredakteur der niemals um kesse Sprüche verlegenen Wired, hat das „Ende der Theorien“ ausgerufen. Er interpretiert Big Data, wie man seinerzeit Data Mining interpretierte, nämlich hypothesenfrei. Jedoch, Hypothesen‑ und damit Theoriefreiheit gibt es nicht. Jedes Datenanalyseverfahren kann nur eine Sorte Muster finden. Eine Clusteranalyse findet Gruppen, Entscheidungsbäume finden Wenn-Dann-Beziehungen usw. Damit steckt die Hypothese schon im Verfahren. Das ist aber eher für Wissenschaftstheoretiker wichtig. Wichtiger ist die Frage, wie hypothesenfrei man sein sollte. Man kann Rechenanforderungen beliebig in die Höhe treiben, indem man Vollständigkeit postuliert, was die Big-Data-Version von Theoriefreiheit ist. Wenn etwa ein Versandhändler herausfinden will, welche Merkmale seiner Produkte und Kunden auf häufigere Retouren schließen lassen, dann kann er das theoriefrei tun, indem er alle Variablenkombinationen durchrechnen lässt. Im Controlling vermeiden wir solche Unbekümmertheit. Controller haben keine Supercomputer. Deswegen haben alle unsere Data-Mining-Verfahren eine „Rechenzeitbremse“: Variablen, die nicht relevant sind, schließt man einfach von der Analyse aus. Der Versandhändler Otto berichtete auf einer Konferenz von seinen Retourenanalysen und bestätigte, dass man explizit mit Thesen, also nicht theoriefrei, und nur einigen davon startete. Dass mehr hier nicht mehr sein kann, leuchtet noch mehr ein, wenn man sich die möglichen Handlungsoptionen vor Augen führt. Retouren sind ärgerlich, aber wäre es eine erfolgversprechende Strategie im Versandhandel, Kunden abzuweisen, weil die Maschine eine überdurchschnittliche Retourenwahrscheinlichkeit errechnet hat? Sicher nicht. Schon eher wird man Regeln suchen, die auch dem Kunden einleuchten. Wenn man versucht, bei Otto das gleiche Hemd in 5 Größen zu bestellen, erscheint ein Popup und redet einem ins ökologische Gewissen.

Ein Popup fürs ökologische Gewissen. Quelle: otto.de.
Anklicken zum Vergrößern.
Fallbeispiel 5: Auf Facebook wird mehr Geld mit Machen als durch Analysieren verdient
Ich bin Fan einer starken Verzahnung von strukturierten und unstrukturierten Daten. Facebook steht in der Big-Data-Diskussion beinahe synonym für unstrukturierte Daten und das schadet nicht. Auffällig ist jedoch, dass selten über einige systematische Mängel eines solchen Datenpools nachgedacht wird. Die Güte von Datenauswertung hängt sehr an der Repräsentativität. Die ist in sozialen Netzwerken per se nicht gegeben. Selbst wenn 1.000 Ihrer Kunden sich lauthals auf Facebook über Ihre Produkte beschweren, sagt das wenig darüber aus, was die anderen 99.000 Ihrer Kunden denken. Eine gezielte Umfrage unter nicht einmal hundert halbwegs repräsentativ ausgewählten Kunden wird einen schneller an die Wahrheit bringen. Hinzu kommt, dass Anbieter sich Meinungen und ihre Verbreitung im großen Stil kaufen. Was auf Facebook und anderswo passiert, ist längst nicht mehr ein unschuldiges Datenbild sozialer Phänomene, sondern Schauplatz von Kämpfen um diese Phänomene.

{kind=link}
Kommentare
Sie müssten eingeloggt sein um Kommentare zu posten..